

👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈


![]()
👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
大家好,这里是程序员晚枫,正在all in AI编程实战。
今天给大家分享的是:国人在推特买卖个人信息的案件((2024)皖08刑终13号)。
被告人张三为谋取非法利益,通过使用推特(Twitter)软件发布查询、出售公民个人信息广告,将电报(Telegram)聊天软件作为联系方式进行接单,并通过土豆(Potato)软件联系上家,购买他人户籍信息、开房记录、出行信息、银行卡流水、手机定位、手机号码等公民个人信息,出售给他人。
自2021年12月1日至2023年5月29日,违反国家有关规定,非法获取并向他人出售公民个人信息,违法所得147万元以上,属情节特别严重,构成侵犯公民个人信息罪。
最终对张三的判决有:上诉人张三犯侵犯公民个人信息罪,判处有期徒刑四年,并处罚金人民币一百五十万元;继续追缴上诉人张三违法所得人民币一百二十四万元及收益,上缴国库。
《中华人民共和国刑法》
第二百五十三条之一违反国家有关规定,向他人出售或者提供公民个人信息,情节严重的,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。
违反国家有关规定,将在履行职责或者提供服务过程中获得的公民个人信息,出售或者提供给他人的,依照前款的规定从重处罚。
窃取或者以其他方法非法获取公民个人信息的,依照第一款的规定处罚。
单位犯前三款罪的,对单位判处罚金,并对其直接负责的主管人员和其他直接责任人员,依照各该款的规定处罚。
这一法律规定明确了侵犯公民个人信息的法律后果,旨在保护公民的个人信息安全,防止个人信息被非法获取、使用或泄露。
开了一个免费专栏👉程序员说法:通过分享国内外的互联网犯罪案例,既帮大家规避风险,也是劝人向善。
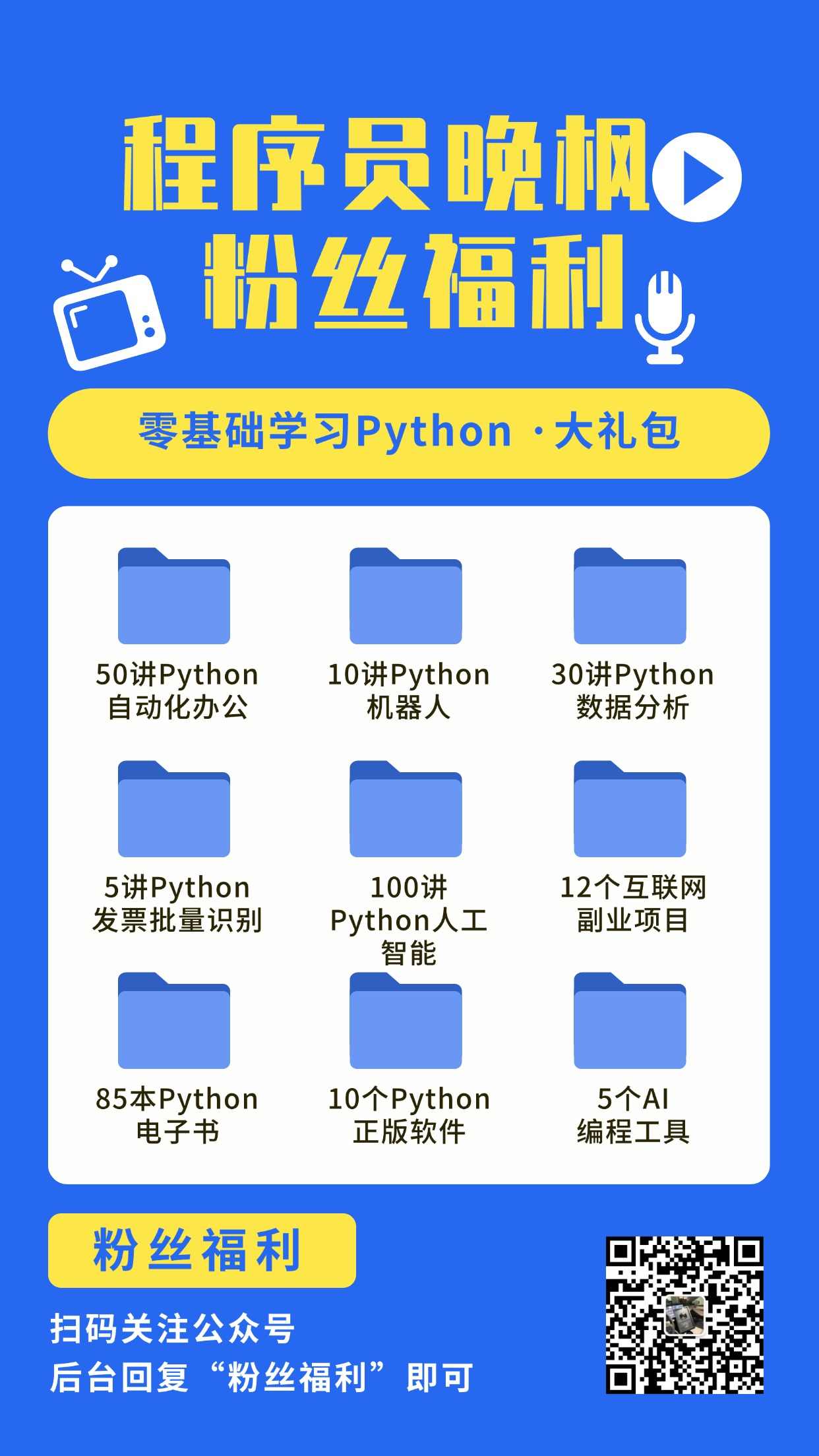


程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
这就是导致你的操作和视频里一模一样,但Excel里是一片空白。
今天我详细给大家说一下,怎么开通权限。
请确保进行下面的操作时,已经购买了我的ocr软件,并且按配套文档已经开通了账号,购买链接:点我直达
有购买问题、使用问题,随时+我微信沟通:点我查看微信二维码
开通账号以后,只需要进行下面的1步操作:

程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
大家好,这里是程序员晚枫,正在all in AI编程实战。
熟悉我的朋友都知道,我的副业项目很多,其中一项就是在网上卖课,我能在毕业的第2年就买房买车,必须要感谢自媒体。当然了更要感谢家长。🐕
今天我全流程给大家分享我在网上卖课的方法和经验。
课程内容,主要确定2点:给谁看?难度有多大?
很多人制作课程,都是站在自己会什么的角度设计课程,然后又抱怨课程卖不出去。
其实应该站在潜在用户有多少的角度设计课程内容。
举个例子:计算机专业的大学生,想卖课赚钱生活费,应该制作一个计算机基础课程,还是制作一个修电脑的课程?
我会建议你做一个修电脑的课,因为不是所有人都需要学习计算机知识,但有更多人需要修电脑。
你细品。
这里要明确一个问题:这套课程是引流用的,还是赚利润用的。
很多人不明白:为什么引流用的还要收费?
这是人性的一个弱点:免费的东西,没人会珍惜,给他也不会认真看。
如果是引流的,建议直接1元,最多9元,个位数就可以了。
引流课程的作用:让他认识到你的价值,然后去买你的利润课程。
利润课程,价格一定要高,高到他随时联系你,你都不会觉得烦。否则,你收了钱也不能心平气和的提供服务,无法维持好用户关系,这行你也干不长。
很多人觉得知识付费就是割韭菜,我不认同。上大学也是需要交学费的,这也是知识付费,难道也是割韭菜吗?
既然收了钱,你就一定要给用户提供价值,哪怕他不用,你要准备好。就像胖东来卖家电,随时准备好去客户家里修家电,甚至准备好了给客户换新的,但客户可能永远都用不上服务。
不能做好质量管理,就不要出来卖,这是底线问题。
不是所有的课程,都需要录制视频。
而且我一直认为文字是最高效的学习方式。
所以你的这套课用什么形式呢?还是看你的用户需求。
甚至有的用户,需要的只是你给他一个方向:想想你刚毕业找工作的时候。在这种时候,你只需要卖给用户一次语音的时间就够了。
酒香也怕巷子深。
卖课之前,想清楚你的用户主要用哪个平台:大学生用B站、女家人用小红书、中年人用抖音、农村人用快手。
另外,如果你哪个平台都没有粉丝,可以直接找我合作。在和我合作的过程中,学习我的涨粉套路,同时涨粉。
我对任何人都不会藏着掖着,我也不怕你学会了离开我,因为我笃定2点:
上面说了一些形而上的经验,现在分享一些实操方法:
我曾经在刚入行的时候,加入了一家直播公司,接受过专业的课程制作训练,我受益匪浅:
收集目标用户的问题 - 对问题进行分类:实践和理论的两类 - 去掉所有理论知识,只需要在最后给出参考资料 - 把实践知识,按时间顺序,分步骤讲解出来
这样你就是一套好的课程了。
是不是有点颠覆之前的认识?千万不要把你的课程,做成教科书。知识付费主要解决的是大家的职场问题,而不是成为一个大学课堂。职场中,大家更需要的是操作步骤,而不是理论知识。谁下了班还想学理论知识啊?
更多课程知识,可以看我之前制作的视频教程:如何通过自媒体实现知识变现?。第一次听可能有点抽象,但这才是更加核心的内容。
如有任何问题,请随时联系我的微信:点我查看微信二维码

另外,大家去给小明的小红书👇账号点点赞吧~!我不想努力了,想吃软饭了。


程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
最近咨询的朋友很多,马上5.1了,大家想的不是出去玩,而是找我学习?
行吧,反正5.1我也是在家里录课、备考:
今天也是应一位读者的咨询,来和大家聊一下财务转码的可能性,以及配套的学习资料。
先说结论:大。
我从2019年开始,干了5年多转码的咨询,成功率最高的有2个岗位:一个是老师,另一个就是财务。
老师转码成功率高,我认为是有充足的时间学习,再加上悠然自得的心态。
而财务转码成功率高,我认为是因为财务转码的选择太多了!
可以做纯技术工作、可以做技术周边工作,例如:财务软件的售前,甚至可以直接进入券商,做量化软件。
其它背景的人,除了纯技术开发,就真没得选。
而且今晚沟通的朋友,本身对建模又有兴趣,所以我建议按照以下方式进行学习:
先学一下编程入门,直接用我的课程就行了:点我直达
然后看这套培训机构的专业课程:https://pan.quark.cn/s/6549fb241d1e
这个也分2步:
先听一个入门的Python + 人工智能:点我直达
这个直接上培训班的课程就行了:https://pan.quark.cn/s/b12ede9d6c1b
这部分学完了我带你做,届时详聊。

我今天也是刚得到知乎官方的回复,我的开源作品又获得了知乎的认证,国内已经有N个平台邀请我加入了。
这是我的开源项目之一,你也可以看一下:点我直达
努力一点,加快学习时间,不然几年都学不完,时间真的很宝贵,其他行业也有很多机会。
用4个月试一下,我认为足够了。
即使转码不成,这段时间也不会浪费,欢迎你跟我一起搞编程副业,我可以带你实现靠代码,副业月入8k。前提是你要把这些课程学完。
学习过程中,遇到任何问题,都可以直接问我。我的微信,👇

程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
大家好,这里是程序员晚枫,正在all in AI编程实战,全网同名。今天继续来讲开源的内容。
上次给大家分享了一个中阶的操作:从零打造你的专属Python第三方库
文章发布后,又有几位朋友联系我,加入了开源项目的开发.
因为很多人是第一次参与开源项目,所以今天来讲一个初阶的操作:零基础,如何参与开源项目?
主要内容包含:开源合作的步骤、需要的技术知识、如何开始第1个任务、如何运营项目。

以1000+star的开源项目点我查看微信二维码为例,给它贡献代码,共有以下几步:
下面逐一介绍一下每个步骤的注意点。
如果你不懂技术,也想参与开源项目,可以直接看本文第五部分:项目运营。
国内常用的开源平台有GitHub,Gitee,atomgit,GitLab。
目前我们用atomgit作为开发平台,代码提交后自动同步到GitHub和Gitee。
所以我们所有的项目,在3个平台都能找到,都有人提交issues或者pr,但是代码只提交/合并atomgit平台的。
用atomgit的原因我也解释一下,主要有2个:
以下几个知识,参与项目之前大家可以学习一下,其中标⭐的请务必看完再参与:
⭐我这些开源项目的设计思路:Python中国的演讲:《非程序员如何学习和使用 Python》
⭐git的知识:
python的知识(不会可以找我要资料):
推荐资料:流畅的Python(第2版)
一些良好的合作意识:例如提交代码后群里及时同步、改别人的代码之前先确认一下等
注册完账号,给我账号+邮箱的时候,可以顺便说一下你的技术背景/感兴趣的技术方向/项目 + 你想从参与开源中得到什么。
如果我觉得手里的项目能满足你的目标,我会根据你的技术背景,给你一些项目任务,从易到难的顺序,一方面让你逐渐熟悉项目,一方面也让我通过难度来了解你的技术水平。

如果我觉得我无法满足你的目标,我也会直接告诉你,毕竟开源合作本来就是基于兴趣和信任,沟通起来会坦诚直接。
在开发过程中,总会遇到各种各样的问题,所以有不懂的及时提问,也是很重要的一点。
这里我也提前说一下关于分支的问题,如果看不懂,请把上文git的知识学完了再来看:
一个开源项目的成功,除了优秀的开发,也需要优秀的运营,比如:
而这部分工作,是很多专注于技术的程序员是没有接触过的,如果你有兴趣,我也会慢慢带着你做。甚至如果你不会技术开发,但是想参与开源项目,只负责运营部分也是可以的。
目前我手里有30+开源项目,运营主要是我自己在做。
今年开始招募开源作者共同开发以后,也慢慢有一些朋友可以独立运营一个项目了,比如:@码匠er,@YaaaKaaang。
大家如果对开源感兴趣,欢迎加入交流群,一起开发学习。

程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
哈喽啊,不知道你们发现没有,百度又有新功能了。话不多说,上图! 
我们从长期趋势来看,很多国家和地区的离婚率越来越高,对应的也加重了我们的工作量。辣么有没有什么办法可以帮助我们从冗杂的工作中解放出来呢? 答案是有滴!
【pobd】库是基于百度的API实现各种证件识别并且生成Excel文件的Python库。
1 | pip install pobd |
1 |
|
只需这2步,就可以轻松解决这个问题啦!而我们的老朋友 api_key 和 secret_key ,不知道怎么申请的伙伴们,留言区见!
1、调接口
1 | base64_image = self.image_to_base64(img_path) |
就会得到像这样的数据
1 | "words_result": { |
2、洗数据
1 | "姓名_男": res['words_result'].get("姓名_男", [{}])[0].get("word", ""), |
结构化提取字段 → 转成 DataFrame
3.成表格
1 | df.to_excel('离婚证信息.xlsx', index=False) |
以上,就完成工作啦。

程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
大家好,这里是程序员晚枫,正在all in AI编程实战,今天给大家分享一个行驶证识别的实用代码。
这个功能来自一位付费用户的定制开发!
【potx-cloud】库基于腾讯的API实现发票识别并且生成Excel文件的Python库。
1 | pip install potx-cloud |
1 | import potx |
大家有任何问题,欢迎加入AI工具交流群,👇

程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
友情提示:课程持续更新中,请一定要添加我的微信👉点我查看微信二维码,我来给你提供课程最新资料
你好,我是程序员晚枫,小红书/B站/抖音/知乎,都叫这个名字。
诚信很重要。有关课程的任何问题,我都负责解答,上面有我的微信👆。
答疑群长期有效,进入方式:+我微信👇,备注:OCR自动化,我来邀请你。
做了几年自媒体了,整理了一些互联网撸羊毛的方法,长期有效。👇
今年夏天我开始更新Vlog了。👇
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
恭喜您解锁这份宝藏资源!
下面是每套课程和对应的资料:
请注意:以下课程中的收费内容,都不需要再次付费,直接找我要即可。我的微信:python-office
视频:点我直达
课程资料:点我下载
源码:https://atomgit.com/CoderWanFeng1/python-office
视频:点我直达
课程资料:点我下载
如果你喜欢以上这些开源项目,欢迎加入我们的开源小组,一起交流学习,一起进步。
加我的微信:python-office,备注:开源
关于项目的介绍:

程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
大家好,我是程序员晚枫。今天我要给大家带来一个超实用的好消息——popdf 已经支持批量 PDF 转 Word 了!是不是很激动?别急,我来手把手教你玩转这个功能。
pip install popdf
之前我就说过,popdf 的核心就是简单暴力。只需要一行代码,你就能轻松把 PDF 转成 Word:
1 | from popdf import pdf2docx |
是不是很简单?小白也能秒上手!
现在,popdf 更是升级了!支持批量转换啦!只需要换两个参数,就能一次性处理一堆 PDF 文件。以下是关键参数的讲解:
input_file 和 output_file**:这组参数用来处理单个文件,适合零散的 PDF 转换。input_path 和 output_path**:这组参数才是今天的主角!input_path 是 PDF 文件夹路径,output_path 是输出 Word 文件夹路径。只要把 PDF 文件丢进输入文件夹,运行代码,Word 文件就自动出来了。批量转换的代码示例如下:
1 | from popdf import pdf2docx |
是不是超方便?再也不用手动一个个转换了!

为了让大家更直观地感受,我再贴一个完整的代码示例:
1 | from popdf import pdf2docx |
记住,路径一定要改成你自己的文件夹路径,否则程序会骂你哦!
我是程序员晚枫,一个热爱技术、爱折腾的开发者。平时喜欢写一些实用的工具和库,帮助大家解决开发中的小痛点。popdf 就是其中之一,希望能帮到更多人。
如果你对这个工具感兴趣,或者有任何问题,欢迎在评论区留言!告诉我你的使用体验,或者提出你想要的功能,说不定下个版本就实现了哦!
快来试试吧,保证让你惊艳!有问题留言区见! 😄
GitHub 项目地址:https://github.com/CoderWanFeng/popdf
如果你喜欢以上这些开源项目,欢迎加入我们的开源小组,一起交流学习,一起进步。
加我的微信:python-office,备注:开源
关于项目的介绍:

朋友们,最近mcp爆火,但好像普通人又用不上?
别着急,百度悄然上线了一款神秘 App“心响”,定位是通用化智能体,不懂技术的小白,也能轻松使用。
而且还完全免费,手机商店下载⏬即用。
免费的 MCP + Agent Use 开放生态,能力随你定义。
尤其是其中的例行任务,是我最喜欢用的:
① 每天8:00,整理5条AI行业的热点新闻,用于粉丝群的日报
② 每天12:00,根据全网热点,构思3条符合自己特色的文案,用于小红书更新
③ 每天15:00,推送预设的「跌破支撑位自动减仓」策略
这款App要实现的是:把时间留给生,把难题交给它❗
其它大厂的智能体还停留在问答的层面,心响已经可以成为你的私人助手了。
虽然其它大厂也发布了紧急上线的PPT,但软件呢?不能只给个期货呀,只有心响是现货,现在下载就可以用的。
这款「AI特种部队」心响,预计在 425 百度的create 大会正式发布,提前开启智能新体验。
从“AI给零件,你拼装”到“直接给你成品”!从心响开始,一起体验通用 AI 带来的无限可能吧!
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。

大家好,这里是程序员晚枫,正在all in AI编程实战,全网同名。
熟悉我的朋友都知道,我的账号内容80%都是关于开源项目的功能文档,剩下20%是关于开发这些功能的周边。
今年开始邀请了小伙伴们参与开源项目的开发和维护,今天就以potx-cloud为例,讲一下怎么成为一个Python库的发布者。
potx-cloud是专门用来调用腾讯云平台的工具库,目前的核心功能是:1行代码,实现文字识别。
1 | pip install potx-cloud |
1 | import potx |
potx的源码,全部在atomgit开源:https://atomgit.com/python4office/potx-cloud,在gitee和GitHub,也都是同步更新的。
1 | git clone https://atomgit.com/python4office/potx-cloud.git |
修改代码后,提交pr到仓库的develop分支即可。
经历过上面几步,你开发的功能,就有机会加入下一个版本里面,给所有人使用了。
为了防止出现问题,目前发布新版本主要是我自己在操作,但我手里的库实在是多,而且我发现小伙伴们的水平并不比我差,只要有责任心,也不会出现大问题。
所以大家对一个库有足够的了解以后,可以根据下面的内容,自己主动实现对该库的发布/更新。
目前所有的python第三方库,都在这个网站托管:https://pypi.org,你需要在这里注册一个账号,注意:名字只能是字母和数字,不建议用标点符号。
注册以后,给我说一下你的昵称,我邀请你成为该库的maintainer,比如potx-cloud库的maintainer有:

在平台收到成为maintainer的邀请后,同意即可。
回到代码目录,请务必通过单元测试,测试完你所有的修改后,再执行下面的操作。
pypi规定,同一个版本号,只能发布一次。
所以发布之前, 请修改2处地方的版本号,如下图所示:
另外说明一下版本号的规则:
主版本号.次版本号.修订号
建议:更新主版本号之前,一定要经过充分讨论和测试!!


在potx-cloud目录下,运行以下命令:
1 | pip install twine |
不要进入script目录!!具体原因可以看脚本是怎么写的。
第一次运行这个脚本可能会报错,因为现在pypi网站时双因子认证了,可能会让你在发布的电脑上,做一些token或者其它双因子认证的设置,根据它提示的文档做就可以了。英文不好,或者干脆找不到也可以问我。
发布以后,请把最新的版本号及时同步到开发小组的群里.
现在pypi官网,已经开始建议使用更为方便的pyproject.toml来管理和发布第三方库了:https://packaging.python.org/en/latest/guides/section-build-and-publish/。
希望新加入的小伙伴可以学习研究一下,对我们第三方库的管理,也进行一个升级换代~
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
PyCharm 2025.1: 统一的 PyCharm、免费 AI 功能、Junie 正式发布,还有更多更新! | PyCharm 博客
您唯一需要的 Python IDE。
PyCharm 2025.1 带来了重大更新,以提升您的开发体验。
PyCharm 现在是一款统一的产品,集成了 PyCharm 专业版和社区版。2025.1 版还带来了免费的 AI 功能、Junie 的公开发布、Cadence 的推出、Jupyter 的重大增强、对 Hatch 的支持、数据整理工具,以及许多其他改进。
您可以通过我们的下载页面获取最新版本,或通过我们免费的 Toolbox 应用进行更新。
阅读这篇博客文章,了解更多更新内容。
更喜欢视频?通过这个视频了解主要新闻和改进:
PyCharm 现在是一款强大、统一的产品!其核心功能(包括 Jupyter Notebook 支持)将免费提供,并且提供带有额外功能的专业版订阅。
从 2025.1 版开始,每位用户都能立即获得免费的一个月专业版试用,因此您可以立即使用 PyCharm 的所有高级功能。试用期结束后,您可以选择继续订阅专业版,或继续免费使用核心功能。有关此更改的更多信息,请阅读这篇博客文章。
JetBrains 推出的编程助手 Junie 现已通过 JetBrains AI 在 PyCharm 中提供。Junie 能够自主规划、编写、优化和测试代码,使您的开发体验更加顺畅、高效和愉悦。它可以处理繁琐的任务,如重构代码、创建测试和实施优化,以便您能够专注于更大的挑战和创新。
JetBrains AI 已获得重大升级,将 AI 助手和编程助手 Junie 纳入单一订阅中。通过此次发布,所有 JetBrains AI 功能在 PyCharm 专业版中免费提供,其中一些功能(如代码补全和本地模型支持)可无限量使用,其他功能则提供基于积分的有限访问。
我们还引入了一个新的订阅系统,让您可以根据需要轻松扩展使用 AI 专业版和 AI 终极版。此次发布的其他亮点包括更智能的补全功能、高级上下文感知,以及对 Claude 3.7 Sonnet 和 Gemini 2.0 Flash 的支持。请访问“新功能”页面,了解更多最新的 AI 功能。
我们推出了 Cadence。您现在可以直接从 PyCharm 在几分钟内将机器学习代码运行在强大的云端硬件上,无需复杂的设置或云端专业知识。Cadence 插件简化了机器学习工作流,使您能够专注于代码,同时利用可扩展的计算资源。
我们实现了数据整理工具,这是一款强大的工具,可帮助 Python 数据专业人员简化数据处理,专注于更高层次的分析。通过交互式界面,无需编写重复代码,即可执行常见的数据框转换(如筛选、清洗、处理异常值等)。
您可以查看和探索列统计信息、自动生成转换的 Python 代码、跟踪更改历史、轻松导出数据,并将转换作为新单元格插入笔记本中。
PyCharm 2025.1 引入了 SQL 单元格。这种新的单元格类型允许您在 Jupyter 笔记本中查询数据库、数据框和附加的 CSV 文件,并将查询结果自动保存到 pandas 数据框中。
我们还引入了许多其他改进,以增强 Jupyter 笔记本的体验。请访问“新功能”页面了解更多相关内容。
我们引入了对 Hatch 的支持,Hatch 是 Python 打包管理局(PyPA)推出的一款现代且可扩展的 Python 项目管理工具。Hatch 可以自动迁移 setuptools 配置、创建隔离环境以及运行和发布构建,使 Python 包管理更加高效。
PyCharm 还允许创建由 Hatch 管理的新项目。当从本地机器或远程源导入 Hatch 项目时,IDE 将自动识别这些项目。
想要了解更多?
我们期待收到您对 PyCharm 2025.1 的反馈 – 请在下方留言或通过 X 平台与我们联系。
如果你喜欢以上这些开源项目,欢迎加入我们的开源小组,一起交流学习,一起进步。
加我的微信:python-office,备注:开源
关于项目的介绍:
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
PyCharm 2025.1: 统一的 PyCharm、免费 AI 功能、Junie 正式发布,还有更多更新! | PyCharm 博客
您唯一需要的 Python IDE。
PyCharm 2025.1 带来了重大更新,以提升您的开发体验。
PyCharm 现在是一款统一的产品,集成了 PyCharm 专业版和社区版。2025.1 版还带来了免费的 AI 功能、Junie 的公开发布、Cadence 的推出、Jupyter 的重大增强、对 Hatch 的支持、数据整理工具,以及许多其他改进。
您可以通过我们的下载页面获取最新版本,或通过我们免费的 Toolbox 应用进行更新。
阅读这篇博客文章,了解更多更新内容。
更喜欢视频?通过这个视频了解主要新闻和改进:
PyCharm 现在是一款强大、统一的产品!其核心功能(包括 Jupyter Notebook 支持)将免费提供,并且提供带有额外功能的专业版订阅。
从 2025.1 版开始,每位用户都能立即获得免费的一个月专业版试用,因此您可以立即使用 PyCharm 的所有高级功能。试用期结束后,您可以选择继续订阅专业版,或继续免费使用核心功能。有关此更改的更多信息,请阅读这篇博客文章。
JetBrains 推出的编程助手 Junie 现已通过 JetBrains AI 在 PyCharm 中提供。Junie 能够自主规划、编写、优化和测试代码,使您的开发体验更加顺畅、高效和愉悦。它可以处理繁琐的任务,如重构代码、创建测试和实施优化,以便您能够专注于更大的挑战和创新。
JetBrains AI 已获得重大升级,将 AI 助手和编程助手 Junie 纳入单一订阅中。通过此次发布,所有 JetBrains AI 功能在 PyCharm 专业版中免费提供,其中一些功能(如代码补全和本地模型支持)可无限量使用,其他功能则提供基于积分的有限访问。
我们还引入了一个新的订阅系统,让您可以根据需要轻松扩展使用 AI 专业版和 AI 终极版。此次发布的其他亮点包括更智能的补全功能、高级上下文感知,以及对 Claude 3.7 Sonnet 和 Gemini 2.0 Flash 的支持。请访问“新功能”页面,了解更多最新的 AI 功能。
我们推出了 Cadence。您现在可以直接从 PyCharm 在几分钟内将机器学习代码运行在强大的云端硬件上,无需复杂的设置或云端专业知识。Cadence 插件简化了机器学习工作流,使您能够专注于代码,同时利用可扩展的计算资源。
我们实现了数据整理工具,这是一款强大的工具,可帮助 Python 数据专业人员简化数据处理,专注于更高层次的分析。通过交互式界面,无需编写重复代码,即可执行常见的数据框转换(如筛选、清洗、处理异常值等)。
您可以查看和探索列统计信息、自动生成转换的 Python 代码、跟踪更改历史、轻松导出数据,并将转换作为新单元格插入笔记本中。
PyCharm 2025.1 引入了 SQL 单元格。这种新的单元格类型允许您在 Jupyter 笔记本中查询数据库、数据框和附加的 CSV 文件,并将查询结果自动保存到 pandas 数据框中。
我们还引入了许多其他改进,以增强 Jupyter 笔记本的体验。请访问“新功能”页面了解更多相关内容。
我们引入了对 Hatch 的支持,Hatch 是 Python 打包管理局(PyPA)推出的一款现代且可扩展的 Python 项目管理工具。Hatch 可以自动迁移 setuptools 配置、创建隔离环境以及运行和发布构建,使 Python 包管理更加高效。
PyCharm 还允许创建由 Hatch 管理的新项目。当从本地机器或远程源导入 Hatch 项目时,IDE 将自动识别这些项目。
想要了解更多?
我们期待收到您对 PyCharm 2025.1 的反馈 – 请在下方留言或通过 X 平台与我们联系。
如果你喜欢以上这些开源项目,欢迎加入我们的开源小组,一起交流学习,一起进步。
加我的微信:python-office,备注:开源
关于项目的介绍:
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
大家好,这里是程序员晚枫。
作为一个开源项目的维护者,我一直以来都有一个“世纪难题”:我维护了N个开源项目,而这些项目需要同时在GitHub、Gitee和atomgit三个平台上同步。每次更新代码,我都得像一个“人工同步器”一样,挨个平台手动提交,简直累到怀疑人生。
直到本周,我才发现,原来有“仓库镜像”这个神器!只要配置得当,一次提交就能实现三个平台的自动同步。简直是开源维护者的福音!今天,我就以我维护的python-office项目为例,手把手教大家如何用atomgit的仓库镜像功能,轻松搞定多平台同步。
作为一个程序员,我深知开源项目的重要性。GitHub是国际主流,Gitee是国内首选,atomgit则是国产代码托管平台的后起之秀。为了让更多开发者能方便地访问我的项目,我不得不在三个平台上都维护一份代码。
但问题是,每次更新代码,我都得重复以下操作:
这还不算完,有时候还会遇到网络问题,导致同步失败,还得一个个平台排查问题。这种重复劳动,简直是对程序员尊严的挑战!
就在本周,我偶然发现了atomgit的“仓库镜像”功能。简单来说,它允许你将一个平台的仓库自动同步到其他平台。也就是说,只要在atomgit上配置好镜像,我只需要在atomgit上提交一次代码,就能自动同步到GitHub和Gitee!
这个功能简直让我拍案叫绝!为了验证它的效果,我决定用python-office项目来测试。
python-office为例,手把手教你配置仓库镜像如果你还没有在atomgit上创建仓库,先去atomgit官网(https://atomgit.net)注册账号,然后创建一个新仓库。
在atomgit上提交一次代码,观察GitHub和Gitee是否自动更新。如果一切正常,恭喜你!你已经成功实现了三平台同步!
如果你也遇到过类似的多平台同步问题,或者对仓库镜像功能有疑问,欢迎在评论区留言!我会第一时间回复你。
另外,如果你觉得这篇文章对你有帮助,记得点赞、收藏并转发给更多需要的程序员朋友!让我们一起告别“人工同步器”的苦日子,拥抱高效开发!
晚枫碎碎念:
写完这篇文章,我突然觉得,程序员的幸福感其实很简单——找到一个能节省时间的工具,就能开心一整天!希望这篇文章能帮到更多像我一样的开源维护者。如果atomgit的仓库镜像功能能让你少掉几根头发,那这篇文章就值了! 😄
互动话题:
你有没有遇到过类似的“重复劳动”问题?你是怎么解决的?快来评论区分享你的故事吧!
封面提示词:程序员、多平台同步、仓库镜像、GitHub、Gitee、atomgit、代码仓库、效率提升
如果你喜欢这个开源项目,欢迎加入我们的开源小组,一起交流学习,一起进步。
加我的微信:python-office,备注:开源
关于项目的介绍:
另外,大家去给小明的小红书👇账号点点赞吧~!我不想努力了,想吃软饭了。
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
再推荐3个编程大模型:推荐3个免费的AI编程大模型,全部来自BAT
学习之前,建议看一下这篇文章,这是我在2023年的Python中国大会上分享的一个观点:

程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
再推荐3个编程大模型:推荐3个免费的AI编程大模型,全部来自BAT
学习之前,建议看一下这篇文章,这是我在2023年的Python中国大会上分享的一个观点:
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
再推荐3个编程大模型:推荐3个免费的AI编程大模型,全部来自BAT
学习之前,建议看一下这篇文章,这是我在2023年的Python中国大会上分享的一个观点:
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true