

👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈

![]()

👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
大家好,这里是程序员晚枫,正在all in AI编程实战,全网同名。
朋友们,最近的几个周末,几乎不要钱的外卖吃爽了吧?
如果你喜欢这个开源项目,欢迎加入我们的开源小组,一起交流学习,一起进步。
加我的微信:python-office,备注:开源
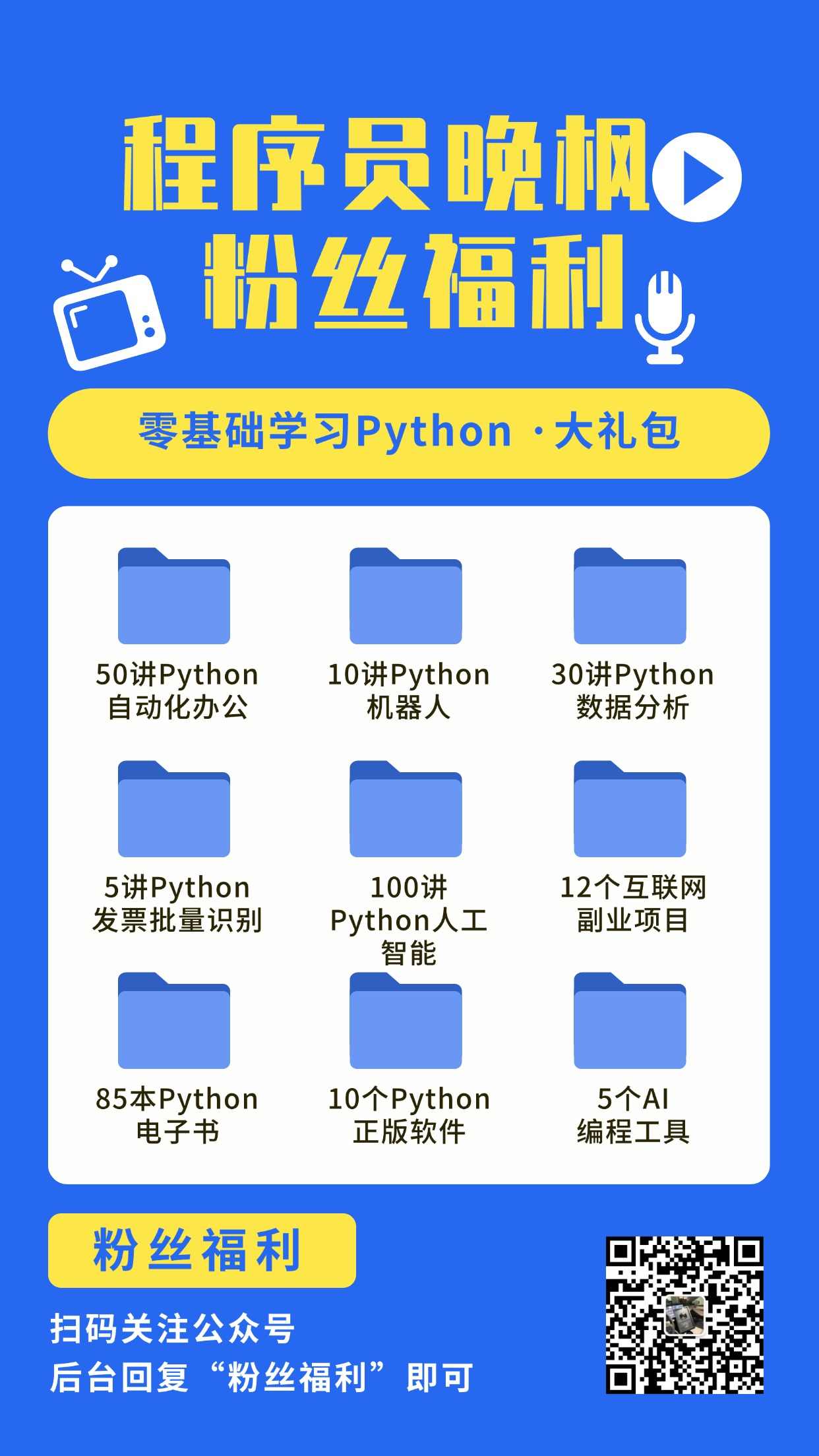
关于项目的介绍:

另外,大家去给小明的小红书👇账号点点赞吧~!我不想努力了,想吃软饭了。




程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
大家好,这里是程序员晚枫,正在all in AI编程实战。
一个月前,开通了一个1999/年,赚不到钱就退费的副业1对1私教服务。随着一个月密集的沟通,大家进步很快,陆续都有了产出。
我最近在修改大家稿件的过程中,也陆续发现了一些问题。
今天我就以逐字修改一位大哥制作的视频中遇到的问题为例,总结一些自媒体视频制作中:绝对不能出现的内容!
虽然我是编程博主,但加入我的副业私教,并不一定要做技术项目。
我的副业私教,服务重点是通过1对1的沟通,教给大家怎么做流量体系、怎么设计变现路径,在网上通过自媒体给用户提供产品/服务,合理合法的增加收入。
你可以是做视频、写文章、运营社群中的一项,也可以全部都干。只要你时间允许。
而且有了这套流量体系,你可以销售自己的产品,比如今天这位大哥他想在抖音/小红书,通过短视频带货儿童玩具。
我的私教,主打一个实操教学。为了避免空谈做视频的理论,我近期有一个需要销售的软件需要录制一个演示视频,于是就给他尝试一下:
大家也想通过这种实操的方式,学习怎么在网上做副业的话,可以+我的微信:点我查看微信二维码,加入我的1999/年的副业私教,服务器内,赚不回门票全额退费。
按照标准的工作流程,一条自媒体视频的制作流程有:
我今天这篇文章主要针对审核环节出现的问题,进行总结复盘。其它环节的问题,都在前期和大哥沟通过了,想知道的小伙伴,也可以在私教群里和我沟通。
另外为了节约时间,我这里也只说问题,没必要玻璃心。好的地方我在私信过程中都说过了。
这是发布后的视频:开发了一个软件!给财务人的发票批量识别.exe,自动化办公你值得拥有
下面是存在的问题:
因为我做了6年的博主,积累了一些粉丝和付费内容,如果大家加入了我的副业私教后没有自己的产品,也可以直接卖我的。
我也给大家说一下合作模式:
像今天这个软件,大哥录完视频以后,来咨询的粉丝我就会直接拉个群,让大哥来对接收钱,软件498元/套。
分成比例:大哥负责销售40%、开发软件的伙伴40%、我的渠道成本20%
而且销售这种软件也不需要会技术,会用视频里这个软件就行了。鼠标点一点,能教给客户怎么用,软件出了bug,我们也有开发小伙伴进行答疑和修复。
其它课程、软件,也是类似的合作模式。感兴趣的朋友可以加微信:点我查看微信二维码 咨询 ~
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
大家好,这里是程序员晚枫,正在all in AI编程实战。
这是一篇随着我的经历和收获增加,不定时更新的自我介绍。
临沂人,广州上学,佛山工作过,现在重庆。
2012.09-2016.07 本科 电子信息科学与技术
2016.09-2019.07 硕士 知识产权
2019.07-2021.08 佛山 Java & Python程序员
2022.01-2022.08 重庆 Python程序员
2023.01-2025.01 重庆 C++ & Python程序员
2025.01-现在 重庆 数据合规专员
全网同名:程序员晚枫,起步于B站/公众号:Python自动化办公社区
短视频重点运营的平台是:小红书:程序员晚枫
泰国、尼泊尔、俄罗斯、澳大利亚
驾驶证
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true
