
你好,以下是付费资料:
85本书
网盘链接:https://pan.quark.cn/s/75c52d3cbfff
提取码:pk66
Excel自动化办公(Pandas)
网盘链接:https://pan.quark.cn/s/d83ddd4c081a
提取码:pvA3
付费读者群
👇添加我的微信,备注:85,我来邀请您~

2、交流群 & 学习资料




你好,以下是付费资料:
网盘链接:https://pan.quark.cn/s/75c52d3cbfff
提取码:pk66
网盘链接:https://pan.quark.cn/s/d83ddd4c081a
提取码:pvA3
👇添加我的微信,备注:85,我来邀请您~
你好,这里是程序员晚枫,B站账号:Python自动化办公社区,里面有很多免费学习资料哟~👇
图片
言归正传,本套资料是85本Python电子书,主题有:Python基础、数据分析、爬虫、网站、机器学习、AI、编程导论、自动化测试、自动化办公等多种类别,几乎涵盖了所有Python学习方向。以下是部分电子书的截图:
图片
学习编程,除了看书,如果能有视频和答疑群,学习效果就更好了。所以本套资料,还给大家提供了以下视频教程+答疑群:
为了体现出读者福利的特点:以上所有资料一起,付费本文9元(90个微信豆)后,全部都可以自动获取!👇
想白嫖Python学习资料的朋友,可以去看一下我的免费学习网站:www.python-office.com,有除了本文以外的其它学习资料。
付费本文后,文末会自动出现:①电子书的网盘地址、②视频课程的网盘地址(视频、代码、软件、文档)、③我的微信二维码(邀请进读者群)。
另外说一下,付费后,提供我的微信二维码还有一个意义:如果你付费本文下载资料后,觉得资料太多了,不知道学哪个对自己有用,你也可以+我的微信说一下你的需求,我给你从这些资料里面,挑出对你最有用的。(只针对付费本文的用户)
↓↓付费后正下方,会自动出现以上资料的网盘下载链接,永久有效↓↓
图片
Python安装包
首先是Python的安装,提供了3个版本的教程:
其次是编辑器,安装完Python才走完了第一步,如果没有编辑器,只有Python在哪里写代码呢?
如果安装完了还不过瘾,大家可以学习以下入门课程,都是适合小白的实用案例课:
扫码下图,直达群聊。👇



👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
今天咨询的主题是:自己学完Python基础了,如何继续深入学习,达到实用的水平?
咨询一共分为3个阶段:确定目标、学习计划和结尾答疑。下面是每个阶段的总结和资料:
已经学过变量、流程控制,但是没专门学过第3方库,也没学过Python高级语法。
自己的目标是:办公用 + 副业接单,不考虑干程序员。
针对这个目标,有4个学习方向可以选择,从易到难分别是:自动化办公、数据分析、爬虫、后端。
其中自动化办公和数据分析较为简单,可以用来自用;爬虫和后端难度较大,用来接单。
针对这个目标,学习以下内容,可以快速达到实用的水平。
学习一套课程就可以了:给小白的《50讲Python自动化办公》,视频和配套资料如下:
数据分析是个非常宽泛的方向,这里推荐一套办公通用的数据分析课程。
从爬虫开始,就涉及Python专业开发的内容了,本来应该学习3~6个月。
但因为你不想从事程序员,所以推荐一套日常够用的课程,先全面的掌握以下,如果学完觉得还有余力,可以找我要更专业的课程。
后端课程,只需要学习一个框架:Django,这是市场的主流框架,适合接单。
一定要学完爬虫,再来学后端,不然学不明白。知识是循序渐进的!
这一部分,L问了一个问题:能不能用代码解决办公中的问题?
回复如下:
大家好,这里是程序员晚枫。国庆假期,大家去哪里玩耍了?
这个假期我哪也没去,一直待在家里更新课程:给小白的《50讲Python自动化办公》,截止今晚的这篇文章发布,已经更新到第41讲了。
课程全部更新完成,目前78元就可以拿下,长期有效。
假期在家里学习的同学,赶紧冲:点我领取
这篇文章,给大家分享一个有用的课程知识:使用清华大学的镜像,下载Python自动化办公的代码。
我们的课程,围绕Python自动化办公的专用库:python-office展开,然而下载python-office,需要去远在国外的仓库下载,速度非常慢,甚至有的朋友还会下载失败。
所以我们可以使用清华大学提供的免费镜像,快速下载我们的代码。命令如下,👇。
1 | pip install -i https://mirrors.aliyun.com/pypi/simple/ python-office |
使用方法也非常的简单,我在课程第3讲专门讲了使用方法,大家一定要去看一下。
不夸张的说,速度提升了100倍!
图片
大家在学习课程中有任何问题,欢迎+微信和我交流~我的联系方式:微信、读者群、1对1、福利
大家节日快乐,这里是程序员晚枫,小红薯也叫这个名字。
今天给大家分享一个实用功能:自动群发祝福消息。
我相信社会人都体会过,过年过节给别人群发祝福消息的无奈,今天分享的这个工具,可以快速的解决这个烦恼。
我们一起来看一下使用方法吧~
自动群发的功能,来自一个Python第三方库:python-office,使用下面这行命令,可以免费下载和安装:
(如果没安装Python的朋友,可以去我主页看一下Python的免费安装教程哟)
1 | pip install python-office |
国内的朋友,建议使用清华镜像进行安装,使用下面这条命令:
1 | pip install python-office -i https://mirrors.aliyun.com/pypi/simple/ -U |
下载完成以后,运行以下代码,即可实现自动群发。
1 | import office |
运行这行命令以后,会出现一个加载页面,如下图所示。👇
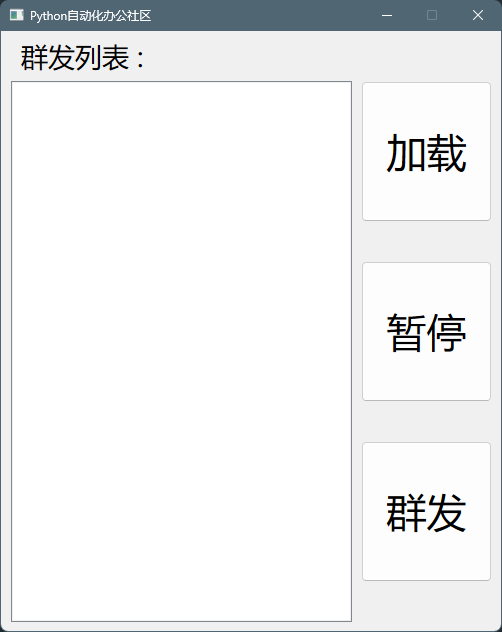
你可以在里面填写2个内容:

这个功能,不仅可以用于群发节日祝福,平时需要群发任何消息,都可以使用。例如:群发广告。
虽然不建议发广告打扰大家,但它是具有这个功能的。
使用代码中,有任何问题,欢迎大家在评论区和我交流哟~

大家好,这里是程序员晚枫,小红书也叫这个名字。
最近在B站更新一套课程:给小白的《50讲Python自动化办公》,并且建了一个课程群,用来沟通大家的学习问题和需求。
在更新课程的这1个多月里,又发现了一些新需求,今天整理出来,分享给大家~
全是自动化办公的常用工具,网友:早知道就好了
电脑空间不够用了?别怕,批量压缩一下文件吧~
1 | pip install pofile |
代码
1 | import pofile |
在网上下载的资料,名称上有广告?直接批量删除。
安装第三方库
1 | pip install python-office |
代码
1 | import office |
根据标题查找文件,大家都用过了。
如果我忘了标题,根据文件里的内容查找文件,你用过吗?
安装第三方库
1 | pip install python-office |
代码
1 | import office |
在没有Python之前,处理数据的软件,非Excel莫属!
安装第三方库
1 | pip install poexcel |
代码
1 | import poexcel |
有多少人文件夹乱七八糟的,自己又不想整理?
用1行Python代码,可以根据文件类型,自动分类整理,赶紧试试~
安装第三方库
1 | pip install pofile |
代码
1 | # 导入这个库 |
以上功能,都来自python-office这个自动化办公的专用库,更多功能和视频教程,可以百度一下:python-office
👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
我工作中的主力语言是C++,在工作之余我搜集了很多有特色的自动化办公代码:可以用1行代码,帮助编程小白解决复杂的办公问题。
下面给大家分享其中的10个代码对应的演示视频。👇
听起来十分复杂的操作,竟然也能用1行代码搞定。
1 | # -*- coding: UTF-8 -*- |
很多PDF转Word的软件需要收费,用Python不收费,速度还很快呢!
1 | # -*- coding: UTF-8 -*- |
用手机看PPT、分享给别人都很麻烦,那就用Python转成1张长图吧!
1 | # -*- coding: UTF-8 -*- |
数据分析,少了Excel怎么行?👉连微软都把Python加入Excel了
1 | # -*- coding: UTF-8 -*- |
作为博主,被抄袭是一件既开心又烦恼的事情。开心的是自己的作品被抄袭说明有流量了,烦恼是流量给了别人…
用1行代码,给所有图片加个水印吧。
1 | # -*- coding: UTF-8 -*- |
文件搜索软件我也用过,但是能通过内容搜索的功能,我只发现Python做到了。
1 | # -*- coding: UTF-8 -*- |
下面这种词云图片,大家都不陌生了吧?如果告诉你用1行Python代码就可以制作,你想不想学习一下?
1 | # -*- coding: UTF-8 -*- |
这么多好用的功能,怎么分享给朋友们呢?自己打包一个exe软件吧!
1 | # -*- coding: UTF-8 -*- |
提起Python,你肯定听说过爬虫吧?1行代码就实现的爬虫,听说过吗?
1 | # -*- coding: UTF-8 -*- |
现在人工智能怎么火,怎么能少了微信聊天机器人,1行代码直接用,再也不怕学习成本大了。
1 | # -*- coding: UTF-8 -*- |
这次我整理了50个自动化办公的实用共鞥你,都是1行Python代码就能实现的,录制了给小白的课程,需要可以加入学习哟~
大家学习 或 使用代码过程中,有任何问题,都可以加微信和我交流哟~👇

👉 项目官网:https://www.python-office.com/ 👈
👉 本开源项目的交流群 👈
![]()
欢迎学习给小白的《50讲 · Python自动化办公》,课程正在持续更新中🚀,每一节课都包含:视频、文档、代码、软件和答疑群,点我下载。
本次课程的特点有以下几个:
本套课程的代码,全部来自开源中国推荐项目,Python自动化办公的专用库:python-office:重磅!官网发布第三方库:python-office,为Python自动化办公而生
目前已经更新了27讲内容,国庆期间会更新完成全部50讲。
以下绿色文字,均可点击直达课程👇
课程前3讲,主要是Python环境的搭建,包含:python的安装、pycharm的安装和pip的使用。
是学习本套课程、运行课程中的代码必须安装的软件。
如果是小白,请务必按顺序听完学会;如果是已经安装并且会使用的大佬,请直接跳转到下一部分的课程。
为了方便大家的学习,课程核心部分:每一讲都是一个单独的案例,互相之间没有知识点的关联,你可以不用按顺序学习,用到哪个就点开哪个。
读者里大佬很多,下面是粉丝的投稿视频,相关代码也在我们的课程资料里。

如需获取本套课程配套的全部:代码、文档、视频、软件、答疑群,可以付费本套合集。👇
2个付费渠道:B站和微信公众号,2选1就行。悄悄说:B站购买更优惠
苹果手机,通过B站购买,更加优惠哦
付费后,2个平台都会自动出现百度云链接,永久有效。
购买资料 或者 学习过程中有任何问题,也欢迎+我的微信交流👉python-office
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true