
大家好,这里是
码匠er,我是【potx-cloud】库的核心开发。今天我很高兴与大家分享近期对【potx-cloud】库的优化成果。这个库最初基于腾讯的API实现发票识别,然后进一步封装为一个方便生成Excel文件的Python库。随着使用场景不断拓宽,我注意到库内有一些设计和实现细节还可以进一步优化,对于这个库的易用性和性能要求也越来越高,于是我启动了本次全面优化计划今天就给大家讲讲这些改进点,咱们一探背后的技术细节。
1. 【potx-cloud】库
简单来说,这是我基于腾讯 OCR 接口封装的工具库,专门解决「发票识别 + 数据整理」的痛点。
你只需要传入发票图片、PDF 或者在线链接,它就能自动识别发票信息,生成带表格的 Excel 文件!
2. 六大优化点,全是干货!
2.1 通用发票识别逻辑优化
原版通用发票识别接口在不传入sub_type参数时不会生成数据,用户必须先知道发票类型才能用。这显然不是理想的体验。此次升级改进如下:
- 若未传入sub_type,系统将识别图片中所有的发票
在处理数据的过程中,如果sub_type是None,就不跳过继续处理。

- 生成的Excel文件会根据发票的类型分别生成不同的sheet,结构更清晰
生成excel过程中,查看当前类型的sheet是否存在,如果不存在,就创建一个新的sheet保存数据;如果存在,就将数据追加保存在之前已经存在的sheet中。
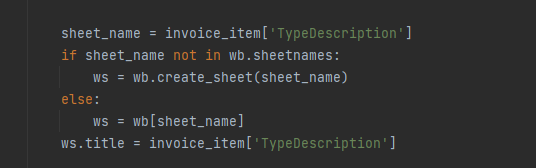
如果存在发票中有需要明细列,重复保存会有很多冗余数据。我本次将公共的代码参数合并。
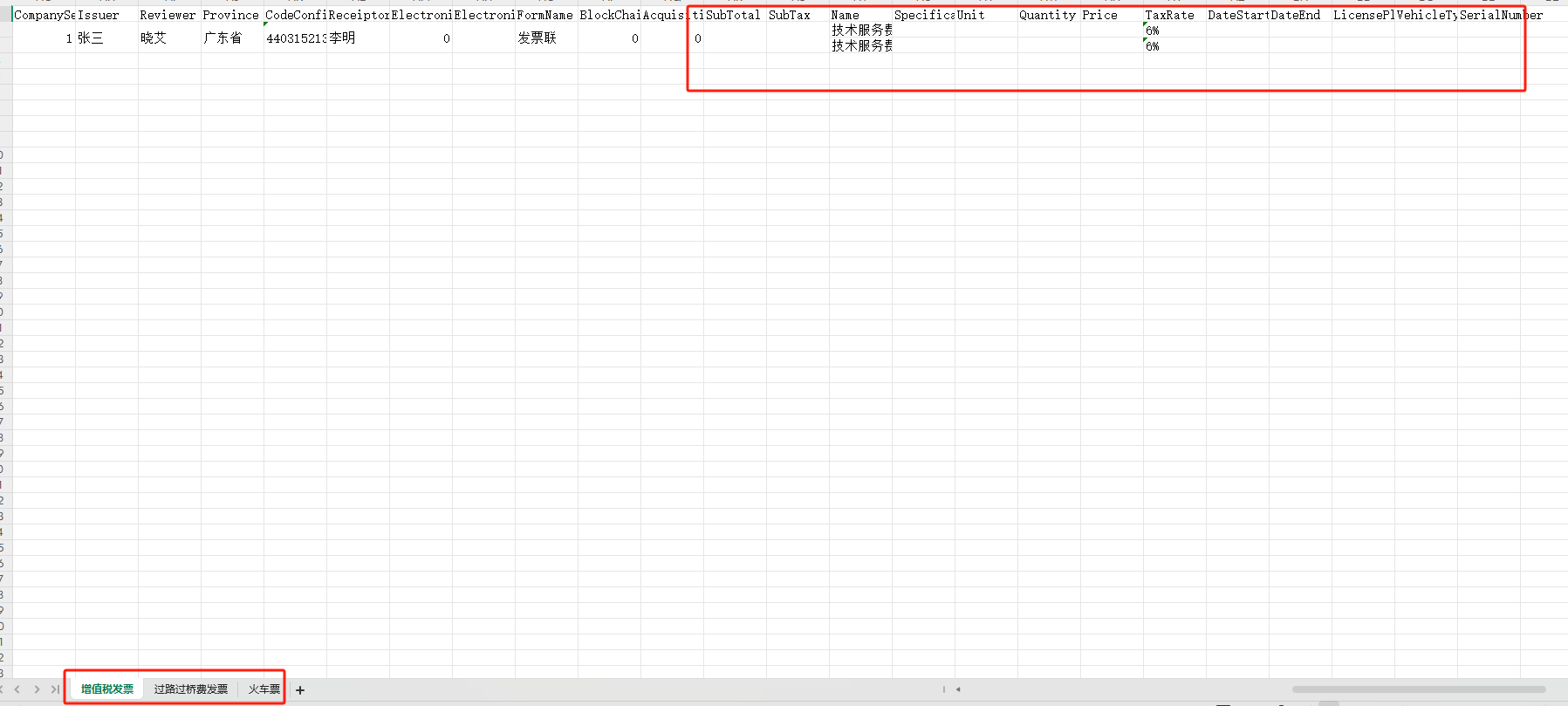
- 对于发票识别中列表数据(比如多行商品明细),公共参数会被合理合并到单元格内,确保数据展示更加整洁美观
- 由于存在明细列的话,腾讯的api会返回把数据以
list类型的数据返回,所以先获取list类型和非list类型的数据;
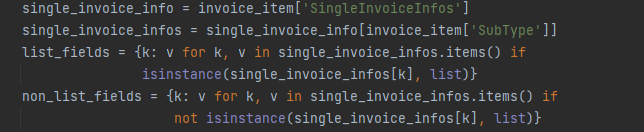
- 将公共数据和
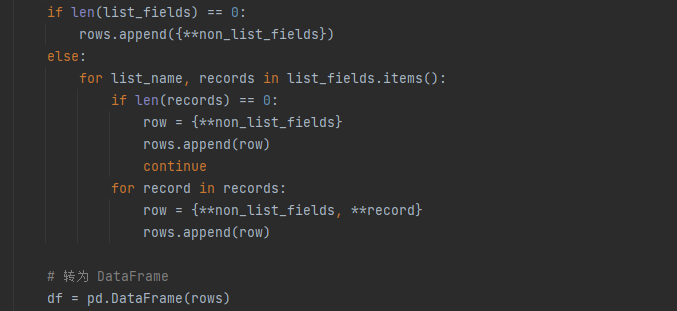
list列表中的数据拼接起来,组成excel中一行数据,如果没有list类型数据,则不需要处理;
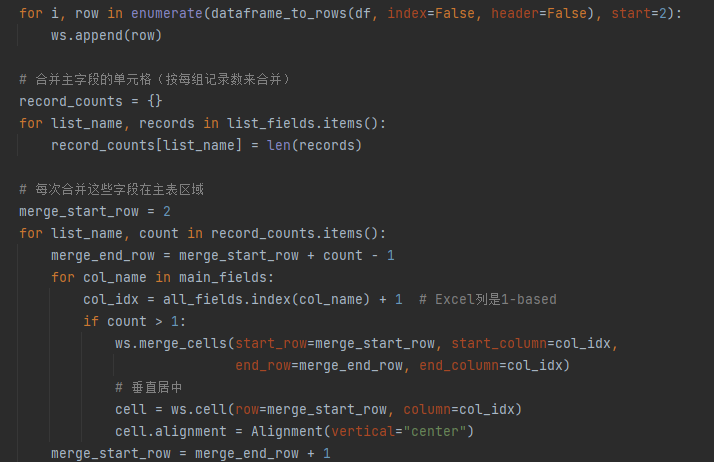
- 所有数据写入之后,获取公共参数的列,将所有的公共列进行合并,然后将之前的数据垂直居中,更好的显示数据;
- 效果展示
2.2 PDF性能优化
腾讯API接口对PDF页数有限制,之前遇到一个需求需要处理25页的发票PDF,处理一次需要44s。如下图:

我按接口最大限制拆分,引入多线程技术使用多个线程同时处理PDF文件,实测处理速度提升5倍以上,极大提升用户体验,确保在实际应用场景下能够更快地返回结果。
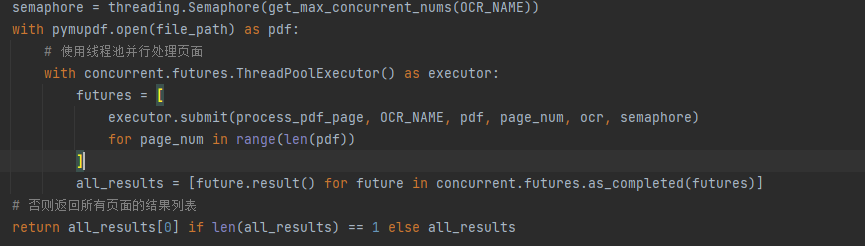
使用线程池,然后根据产品文档中每个接口每秒处理最大的限制控制信号量,然后处理文件。现在我们继续用上面25页的PDF文件来测试,仅仅需要5s左右哦!

在后续的文章中,我会单独写一篇文章来介绍本次性能优化~
2.3 文件格式判断前置
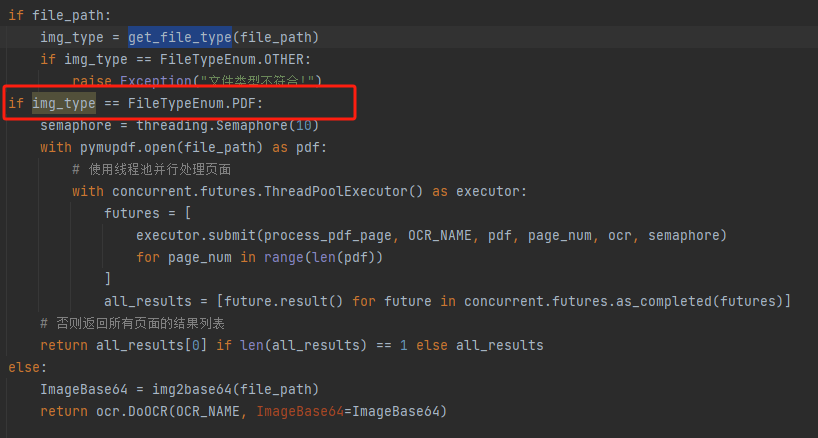
之前,文件类型的判断逻辑是交给调用层自己处理,用户需要根据文件不同类型传入不同的参数,容易出错。现在,我将这种判断提前封装到了do_api.py中:
- 系统在内部根据文件内容自动判断文件类型
- 用户只需要提供统一的file参数
不管你传的是图片还是PDF,我们的库会自己解析文件类型,你只需要关心「文件在哪」,不用再纠结「该传哪个参数」。这种方式大大降低了使用门槛,同时也让代码逻辑更加清晰。
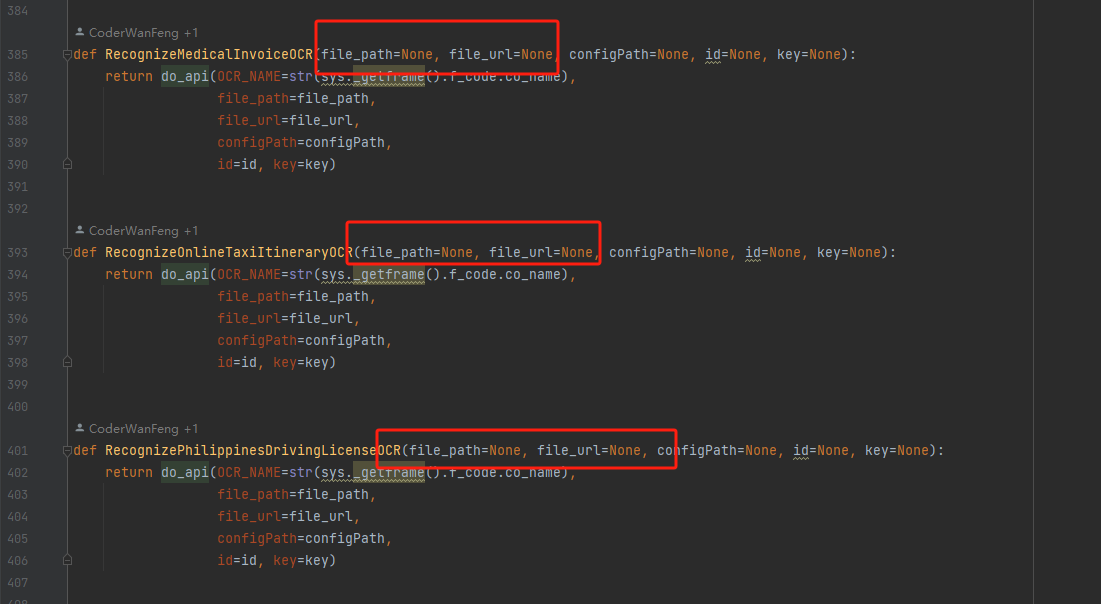
随着文件格式判断逻辑的优化,用户无需再关注文件类型的细节。为此,我对部分参数名称做了重新设计:
- 将原来的
img_path改为file_path - 将原来的
img_url改为file_url
名称的统一更直观地传达出参数的意义,让新老用户都能快速上手。
2.4 参数处理
老版本要求必须传input_path参数,但处理线上文件时,这个参数根本用不上,只需传入img_url参数即可完成,导致用户得写一堆假路径绕过校验。因此,优化后的版本在处理线上文件时对input_path和img_url参数做了更加智能的判断和补偿,用户体验更加友好。

使用在线文件识别时,只需要传入img_url参数。如果input_path存在,优先处理input_path的文件。
2.5 代码结构重构
原先在ocr.py文件中公开了发票识别的接口,然而文件内混杂了诸如get_ocr、do_api、process_pdf_page等辅助方法,这使得代码逻辑显得臃肿,职责不够单一。
为了解决这一问题,我将这些辅助处理逻辑剥离出来,单独封装进了ocr_processor.py文件中。这样一来,ocr.py中的接口将只专注于暴露核心功能,既方便维护,也为后续扩展留下了清晰的接口定义。
2.6 增加测试用例
测试永远是确保代码稳定性的关键。为了验证优化的正确性与稳健性,我增加了针对线上文件接口和PDF文件处理的测试用例。这不仅可以帮助开发者在后续维护中快速定位问题,也为新功能的扩展提供了有力支持。
3. 最后,想和你聊聊我本次开发的体验
本次对 potx-cloud 的重构,核心目标是提升用户体验和代码规范:
- 简化接口设计:通过封装底层逻辑,用户只需关注核心参数,减少了对文件类型的判断和处理。
- 提升处理性能:引入多线程技术,优化了大文件(如PDF)的处理速度,显著提升了整体性能。
- 优化参数命名:统一参数命名,提高了代码的可读性和一致性,降低了使用门槛。
对了,如果你觉得这次优化有点东西,记得「点赞 + 在看」,让更多做发票处理的小伙伴看到这个库~ 咱们下次更新见!
相关阅读
程序员晚枫专注AI编程培训,小白看完他和图灵社区合作的教程《30讲 · AI编程训练营》就能上手做AI项目。
